Useful Tools and Techniques
a. MS Word (v2016 and above) OCR ability:
To take advantage of this ability with MS Word to convert a scan of text (re: a page from a book) to digital-readable output, do the following steps:
a.1 Scan a page via a scanner/smartphone and save as a .jpg or .png file, let's name it, page1.png. Note: Scan in B&W mode if possible.
a.2 Open a graphic-handing app (eg. Photoshop, GIMP etc) and crop the image to remove margins around the text as well as to take measures to any dust marks or unnecessary non-text elements as much as possible. Save the image in Black & White mode.
The open-source app: GIMP is highly recommended.
a.3 Open a blank MS Word document and drag page1.png into it, then print the document, using MS Print to PDF saving the file as cb.pdf
a.4 Open in MS Word the document, cb.pdf. One will find the image now digitalized. It is recommended to copy and paste all the text into a text-editor, such as NotePad++ to remove unnecessary formatting.
b. Cloud-based Services:
b.1 OCR Scanning via Internet (eg. onlineocr.net} Such services take an image of text and returns either a MS word document or the text is a dialogue box where one can copy and paste elsewhere. Note that there is a daily limit of 15 pages for free services for the named website.
b.2 Google Services: As mentioned earlier within these pages, the current Google services such as “Google Drive” together with “Google Docs” provide a shared working environment.
c. File-sharing Scheme: Alternate strategy, certainly for those who have limited Internet access, is to worked by file sharing. The challenge here is to create a ‘versioning’ method to ensure that the latest corrections are maintained and not over-written. One can expressively ‘date’ files so that the latest edition is easily identified; eg. RuhiBk1-Swahili181206.odt, or ascending numbers eg. RuhiBk1-SwahiliV102.odt
d. Usage Reference - Translation History via Embedded Texts
Step one: One needs to create text files (encoding in UTF-8 as to render special characters correctly) of sentence pairs (Engish sentence separated by a marker such as “&&” then the translation such that it is one long connected text - for an example, see Materials
Step two: These sets of sentence pairs will be derived from one translation and will be labelled accordingly, eg. RuhiBk1-SwahiliV102-embedded.txt, and placed in one folder, named say ‘EmbeddedTexts’.
Step three: Using the text editor, the freely available NotePad++ (‘Sublime’ text editor works as well, one activates its Find dialogue (ctl-f) the tab “Find in Files” which allows one to choose this folder ‘EmbeddedTexts’
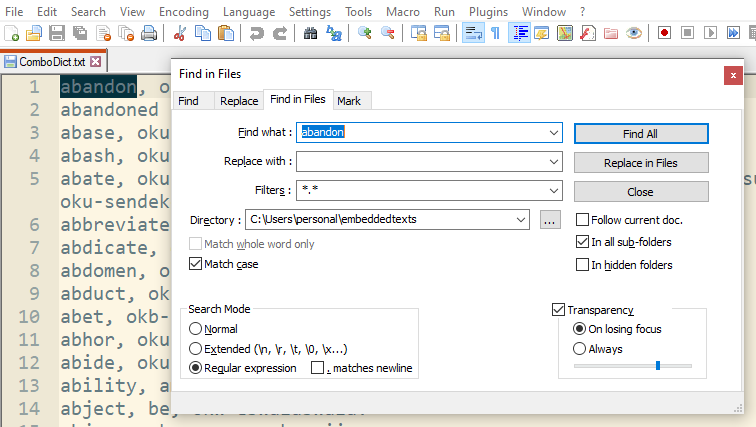
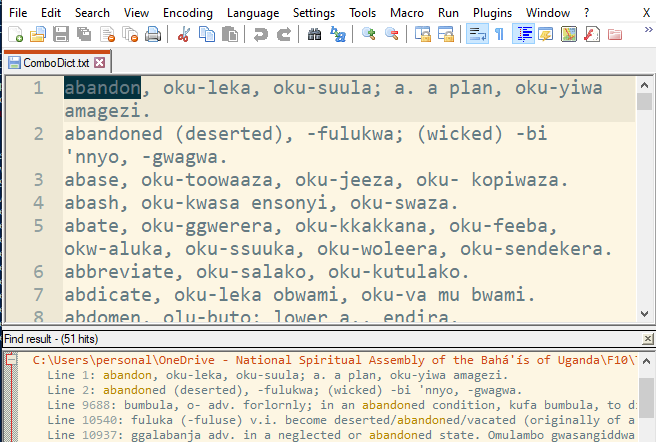
Step four: By this means, the Find function will search through all the text files with the folder, resulting in a list of all the sentence pairs where the target word is found -- or a word listing as in the case of using a dictionary style text as demonstrated below. Clicking on the line reference in the list (found at the extreme right), Notepad++ will bring up the selected text in the editor – all very useful feature for giving word defintion and usage.
| Dynamics | Strategy |
| Materials | Tools |